详情请点阅读全文
上接:https://blog.csdn.net/u010132177/article/details/102911543
概述
1)概念
特征预处理定义(作用):通过特定的统计方法(数学方法), 将数据转换成 算法要求的数据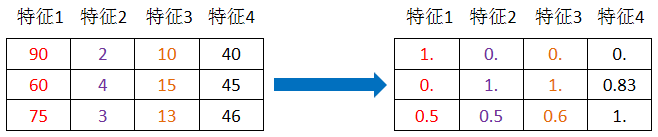

2)特征预处理的方法、种类
1、数值型数据–标准缩放(1-2是重点):
- 归一化
- 标准化
- 缺失值
2、类别型数据:one-hot编码
3、时间类型:时间的切分
3)sklearn特征处理API
计算分2步:x’-x’’:
$$ x’=\frac{x-min}{max-min} $$
$$ x’’=x’*(mx-mi)+mi $$
- 注:作用于每一列,x为每一个值,max为一列的最大值,min为一列的最小值,
X’’为最终结果,mx,mi分别为指定区间值(默认mx为1,mi为0)
例:计算第1列每一个值的归一值:
解:
【第1列,第1项】
x’=90-60/90-60=1
x’’=1*(1-0)+0=1
所以:(第1列,第1项)的归一值为1
【第1列,第2项】
x’=60-60/90-60=0
x’’=0*(1-0)+0=0
所以(第1列,第2项)归一值:0
…
2)sklearn归一化API
sklearn归一化API:
1 | sklearn.preprocessing.MinMaxScaler |
MinMaxScaler语法
- MinMaxScalar(feature_range=(0,1)…)
每个特征缩放到给定范围(默认[0,1]) - MinMaxScalar.fit_transform(X)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后的形状相同的array
归一化步骤
1、实例化MinMaxScalar
2、通过fit_transform转换
归一化sklearn代码例:
对 [[90,2,10,40],[60,4,15,45],[75,3,13,46]] 进行归一化
1 | from sklearn.preprocessing import MinMaxScaler #引入支持 |
3)什么情况能用到归一化(为什么要归一化)案例解释
【例】:相亲约会对象数据,这个样本时男士的数据,三个特征,玩游戏所消耗时间的百分比、每年获得的飞行常客里程数、每周消费的冰淇淋公升数。然后有一个 所属类别,被女士评价的三个类别,不喜欢didnt、魅力一般small、极具魅力large也许也就是说飞行里程数对于结算结果或者说相亲结果影响较大,但是统计的人觉得这三个特征同等重要。
里程数 公升数 消耗时间比 评价 14488 7.153469 1.673904 smallDoses 26052 1.441871 0.805124 didntLike 75136 13.147394 0.428964 didntLike 38344 1.669788 0.134296 didntLike 72993 10.141740 1.032955 didntLike 35948 6.830792 1.213192 largeDoses 42666 13.276369 0.543880 largeDoses 67497 8.631577 0.749278 didntLike 35483 12.273169 1.508053 largeDoses 50242 3.723498 0.831917 didntLike
【计算】此数据在用 [ k近邻 ] 算法对数据进行分类时,红色2列计算为:
(72993-35948) ^2 +(10.14-6.8) ^2 + (1.0-1.21)^2
【分析】可以看到,由于里程数非常大,因此它对数据权重会造成很大影响,所以需要用到归一化使其数值都在(0-1)间从而取消掉过大数值对最终结果造成影响
【目的】:让某一个特征过大时,对最终结果不不会造成非常大影响
【缺点】:如下图,一个不正常(错误)的数据,粉色异常点对最大值最小值影响太大
【应用场景】:注意在特定场景下最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性(即稳定性)较差,只适合传统精确小数据场景。
二、★特征处理:标准化(归一的改进)
1)概述
特点:通过对原始数据进行变换把数据变换到均值为0,标准差 为1范围内
2)标准化公式
$$ x’=\frac{x-mean}{δ} $$
- 注:标准差,作用于每一列,mean为平均值,δ为标准差(考量数据的稳定性)
↓
标准差算法:$$ δ=\sqrt{var} $$
↓
方差算法(var即 variance即):$$var=\frac{(x1- mean)^{2}+(x2- mean)^{2}+…}{n(每个特征的样本数)}$$
↓
方差考量数据稳定性3)计算标准差示例:

解:
(第一列,第一个)
mean=(90+60+75)/3=75
$$ var=\frac{(90-75)^{2}+(60-75)^{2}+(75-75)^{2}}{3} $$
$$ δ=\sqrt{var} $$
x’=90-75/ δ
…
【解析】作用:如果有异常点,对整体影响不大
4)结合归一化来谈标准化

【对于归一化来说】:如果出现异常点,影响了最大值和最小值,那么结果显然会发生改变
【对于标准化来说】:如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小。+
5)sklearn特征化API
sklearn特征化API: scikit-learn.preprocessing.StandardScaler
Standard Scaler:标准 定标器
StandardScaler语法:
StandardScaler(…)
处理之后每列来说所有数据都聚集在均值0附近标准差为1StandardScaler.fit_transform(X,y)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后的形状相同的arrayStandardScaler.mean_
原始数据中每列特征的平均值StandardScaler.std_
原始数据每列特征的方差
代码示例
标准化步骤:
1、实例化StandardScaler
2、通过fit_transform转换
【标准化总结】:在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。
1 | from sklearn.preprocessing import StandardScaler |
三、缺失值处理
1)概述
缺失值主要处理工具:在pandas中即可
缺失值处理2种方法:
- 删除:如果每列或者行数据缺失值达到一定的比例,建议放弃整行或者整列
- 插补:可以通过缺失值每行或者每列的平均值、中位数来填充
2) 缺失值处理sklearn的API: preprocessing.Imputer
API:sklearn.preprocessing.Imputer
2.1Imputer语法:
- Imputer(missing_values=’NaN’, strategy=’mean’, axis=0)
完成缺失值插补 - Imputer.fit_transform(X,y)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后的形状相同的array2.2缺失值处理步骤:
- 初始化Imputer,指定”缺失值”,指定填补策略,指定行或列
注:缺失值也可以是别的指定要替换的值 - 调用fit_transform
2.3关于np.nan(np.NaN)
数据当中的缺失值类型需要是:np.nan - numpy的数组中可以使用np.nan/np.NaN来代替缺失值,属于float类型
- 如果是文件中的一些缺失值,可以替换成nan,通过np.array转化成float型的数组即可
2.4pandas处理缺失值
- pandas:dropna
- fillna
- replace(“?”, np.nan)
2.5缺失值处理示例:
处理缺失值:[[1, 2], [np.nan, 3], [7, 6]]
1 | from sklearn.preprocessing import Imputer |