一、基础概述
1、机器学习开发流程
2、机器学习模型是什么
3、机器学习算法分类
二、需明确问题
(1)算法是核心,数据和计算是基础
(2)找准定位:
大部分复杂模型的算法设计都是算法工程师在做,而我们要做的是:
1.分析很多的数据
2.分析具体的业务
3.应用常见的算法
4.特征工程、调参数、优化三、具体要怎样做
- 学会分析问题,使用机器学习算法的目的,想要算法完成何种任务
- 掌握算法基本思想,学会对问题用相应的算法解决
- 学会利用库或者框架解决问题
四、机器学习开发流程
1 | flowchat |
流程解释
拿到数据:公司固有的数据(包括爬虫得来)、合作得来数据、购买得来
- 确立模型:根据数据类型划分应用种类(据:原始数据、要解决啥问题、确立)
- 数据的基本处理: pd去处理数据(缺失值,合并表。。。。。)
- 特征工程 (特征进行处理)
- 找到合适算法去进行预测:分类、回归
- 模型的评估(判定预测效果):准确率高,进行6步。不高——第4步换算法——还不行,第3步再处理
- 上线使用(以Api形式提供)
4.1机器学习[模型]是什么?
【定义】:通过一种映射关系将输入值到输出值
1 | graph LR |
例如:
- 输入猫、狗、图片,判断它是啥
- 输入 文章,判断它是科技类、还是体育类
- 输入月票房数据,预测下月票房数据
五、机器学习算法分类
5.0 机学两种数据类型(用什么算法的主要判别依据)
数据的类型将是机器学习模型不同问题不同处理的依据
【思考】下图两组数据区别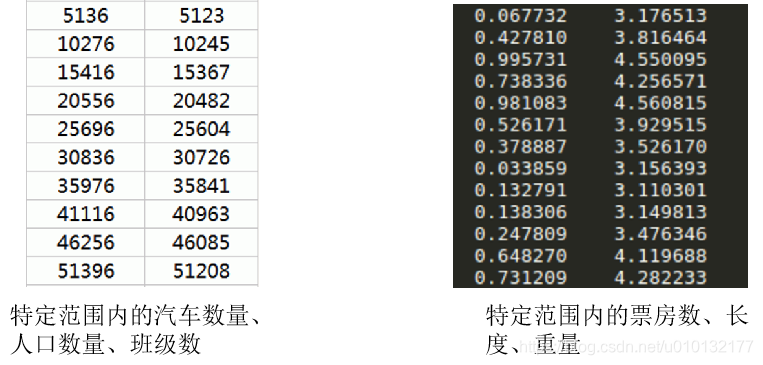
离散型数据:
由记录不同类别个体的数目所得到的数据,又称计数数据,所有这些数据全部都是整数,而且不能再细分,也不能进一步提高他们的精确度
连续型数据:
变量可以在某个范围内取任一数,即变量的取值可以是连续的,如,长度、时间、质量值等,这类整数通常是非整数,含有小数部分。
总结:怎样看是用分类还是回归学习算法?
只要记住一点,离散型是区间内不可分,连续型是区间内可分
【怎样看是用分类还是回归学习算法?】:
目标值是:离散型——分类
目标值是:连续型——回归
5.1监督学习
- 【分类】k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归、神经网络
- 【回归】 线性回归、岭回归
- 【标注】 隐马尔可夫模型 (不做要求)
【监督学习】(Supervised learning),可以由输入数据中学到或建立一个模型,并依此模式推测新的结果。输入数据是由输入特征值和目标值所组成。
函数的输出可以是一个连续的值【称为回归】。
或是输出是有限个离散值【称作分类】。
【监督学习特点】
1 | 【监督学习】---(分类、回归)→ 【输入数据有特征有标签,即有标准答案】 |
5.1.1分类问题
概念:【分类】是监督学习的一个核心问题,在监督学习中,当输出变量取有限个离散值时,预测问题变成为分类问题。最基础的便是二分类问题,即判断是非,从两个类别中选择一个作为预测结果;
分类问题: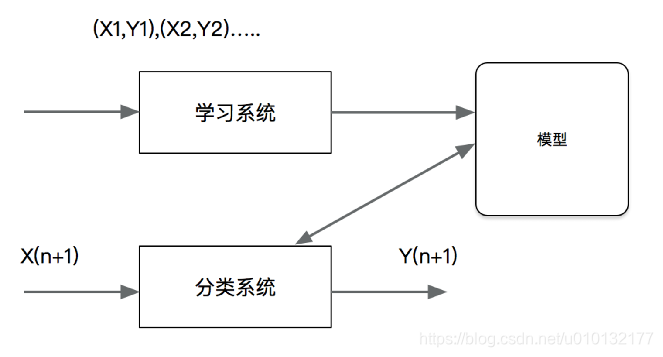
5.1.2分类学习应用:
分类在于根据其特性将数据“分门别类”,所以在许多领域都有广泛的应用:
- 在银行业务中,构建一个客户分类模型,按客户按照贷款风险的大小进行分类
- 图像处理中,分类可以用来检测图像中是否有人脸出现,动物类别等
- 手写识别中,分类可以用于识别手写的数字
- 文本分类,这里的文本可以是新闻报道、网页、电子邮件、学术论文
…5.1.3 回归问题
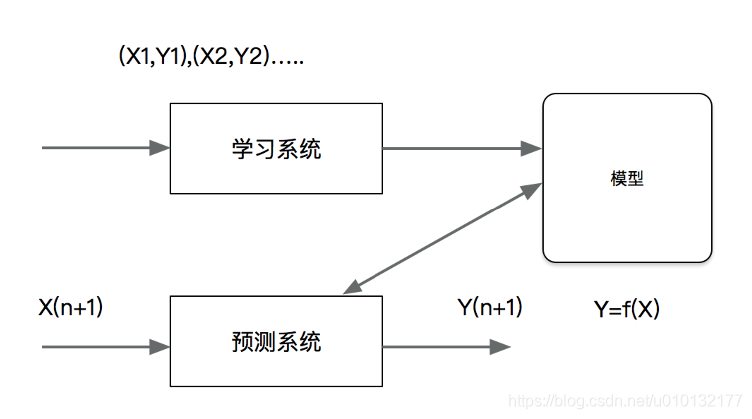
概念:【回归】是监督学习的另一个重要问题。回归用于预测输入变量和输出变量之间的关系,输出是连续型的值。5.1.4回归应用
回归在多领域也有广泛的应用:
- 房价预测,根据某地历史房价数据,进行一个预测
- 金融信息,每日股票走向
…
5.2无监督学习
- 【聚类】k-means
【无监督学习】(Supervised learning),可以由输入数据中学到或建立一个模型,并依此模式推测新的结果。输入数据是由输入特征值所组成。
【无监督学习特点】
1 | 【无监督学习】---(聚类)→ 【输入数据有特征无标签,即无标准答案】 |
5.3习题
说一下它们具体问题类别:
1、预测明天的气温是多少度? ——回归
2、预测明天是阴、晴还是雨?——分类
3、人脸年龄预测?——回归(多重多元回归)
4、人脸识别?——分类
六、★★★机器学习步骤:
- 收集数据
- 用爬虫
- 从RSS反馈或者API
- 设备发送过来的实测数据(风速、血糖等)
- 准备输入数据
- 得到数据之后,还必须确保数据格式符合要求,本书用的是python的list类型数据
- 这种标准数据格式可以融合算法和数据源,方便匹配操作
- 还需要为机器学习算法准备特定的数据格式
如某些算法要求特征值使用特定的格式;
一些算法要求目标变量和特征值是字符串类型,而另一些算法则可能要求是整数类型;
- 分析输入数据
- 目的:此步骤主要是人工分析以前得到的数据,主要作用是确保数据集中没有垃圾数据 为了确保前两步有效,最简单的方法是用文本编辑器打开数据文件,查看得到的数据是否为空值
- 还可以进一步浏览数据,分析是否可以识别出模式
- 数据中是否存在明显的异常值,如某些数据点与数据集中的其他值存在明显的差异。
- 通过一维、二维或三维图形展示数据也是不错的方法,
(然而大多数时候我们得到数据的特征值都不会低于三个,无法一次图形化展示所有特征) - 注:如果是在产品化系统中使用机器学习算法并且算法可以处理系统产生的数据格式,或者我们信任数据来源,可以直接跳过第3步。此步骤需要人工干预,如果在自动化系统中还需要人工干预,显然就降低了系统的价值。
- 训练算法
- 测试算法
- 使用算法